

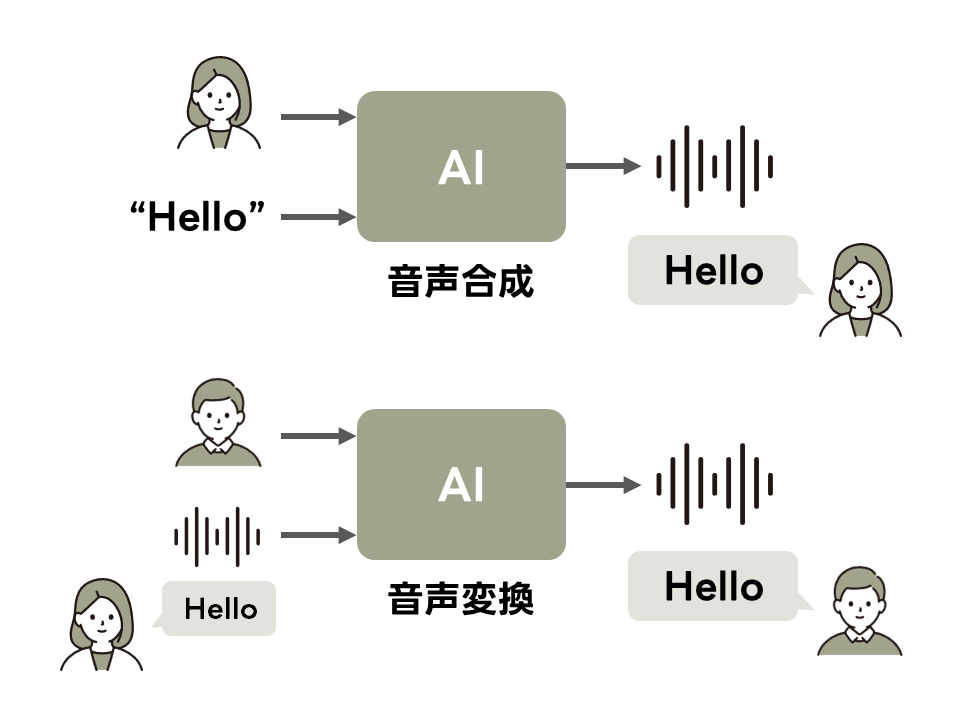
中鹿研究室では、音声合成や声質変換などの研究を行っています。
音声合成とは、テキストから人工的に人間の音声を生成する技術のことです。 この技術はAppleのSiriなどで使われています。最近では、電車やバスでのアナウンスやAI英会話アプリなどでも利用されるようになりました。 また、歌声を対象とした音声合成技術は、初音ミクで有名なヤマハのVOCALOIDなどに利用されています。
声質変換とは、ある人の声を別人の声に変えたり、ある人の声の感情や印象だけを変えたりする技術のことです。 この技術は、言い換えればボイスチェンジャーです。某アニメでは蝶ネクタイ型変声機として登場します。 声質変換の研究が進めば、海外俳優の声質を保った映画の吹き替えや、家族や知人の声で喋るロボットなどが実現できるかもしれません。
これらの技術の実現のために使われるAI(深層学習)は、データから音声の特徴を抽出するために大量のデータを必要とするなど、スマートな解決法とは呼べない場合が多いです。 中鹿研究室では、音声特有のデータ構造をモデル化することによって、少量のデータでも質の高い音声を生成できる技術を研究しています。また、生成音声の悪用を防ぐ方法についても議論を重ねています。
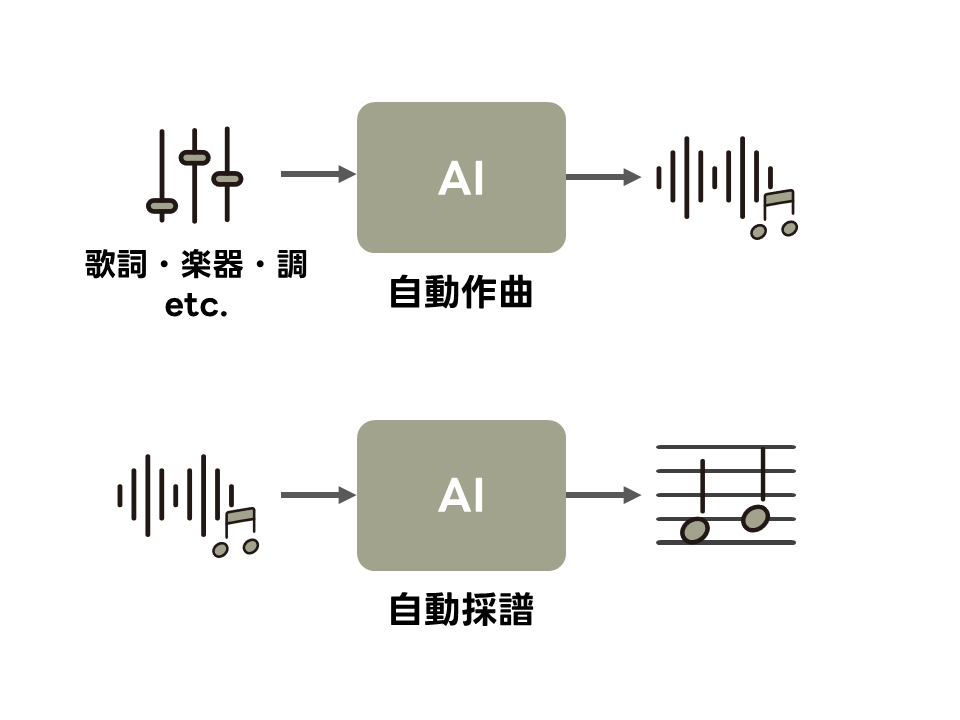
中鹿研究室では、自動作曲や自動採譜などの研究を行っています。
自動作曲とは、ユーザなどから提示された条件に合った音楽を自動で生成する技術のことです。 当研究室の共同研究者である嵯峨山茂樹先生が開発したOrpheusなどで、自動作曲の実証実験が進められています。 最近では、Sunoなどの自動作曲技術を用いたサービスが台頭しています。
自動採譜とは、音源から楽譜を自動で生成する技術のことです。 多くの研究者やGoogleなどの大企業がこの研究に取り組んでいますが、実用化は難航しています。 自動採譜の技術は、音楽の三大要素であるリズム・メロディ・ハーモニーの分析を容易にすると考えられます。 そのため、この分野の研究が進むことで、音楽演奏・制作の効率化やユーザの好みにより合致した音楽の推薦・検索技術の実現が期待できます。
中鹿研究室は、旋律分析や和音推定など音楽情報処理分野の他の研究にも取り組んでいます。 近年この分野ではAI(深層学習)を用いた課題解決が盛んですが、AIの学習のためにデータを大量に用意するのが困難な場合が多いです。 そこで、音楽理論などの事前知識を積極的に活用することで、少量のデータでも性能の良いAI(機械学習・深層学習)を開発することを目指しています。
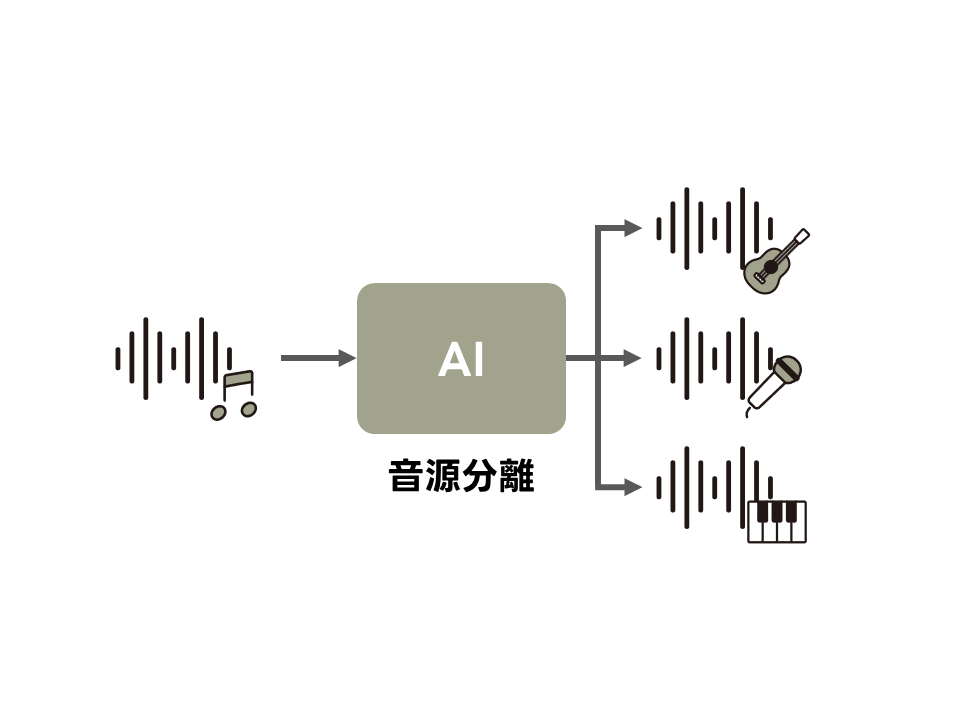
中鹿研究室では、音源分離の研究を行っています。
音源分離とは、複数種類の音が混ざった音源を、各種類の音に分離する技術のことです。 この技術は、Zoomにおけるノイズ除去や、楽曲からボーカル・ベース・ドラムを抽出するサービスなどで使われています。 音源分離の研究が進めば、複数人が同時に話した内容の書き起こしや、より詳細な楽器ごとの音の抽出などの性能が向上するかもしれません。
中鹿研究室では、音声での研究と同様に音響特有のデータ構造をモデル化することで、より効率的に音源を分離できる技術を研究しています。
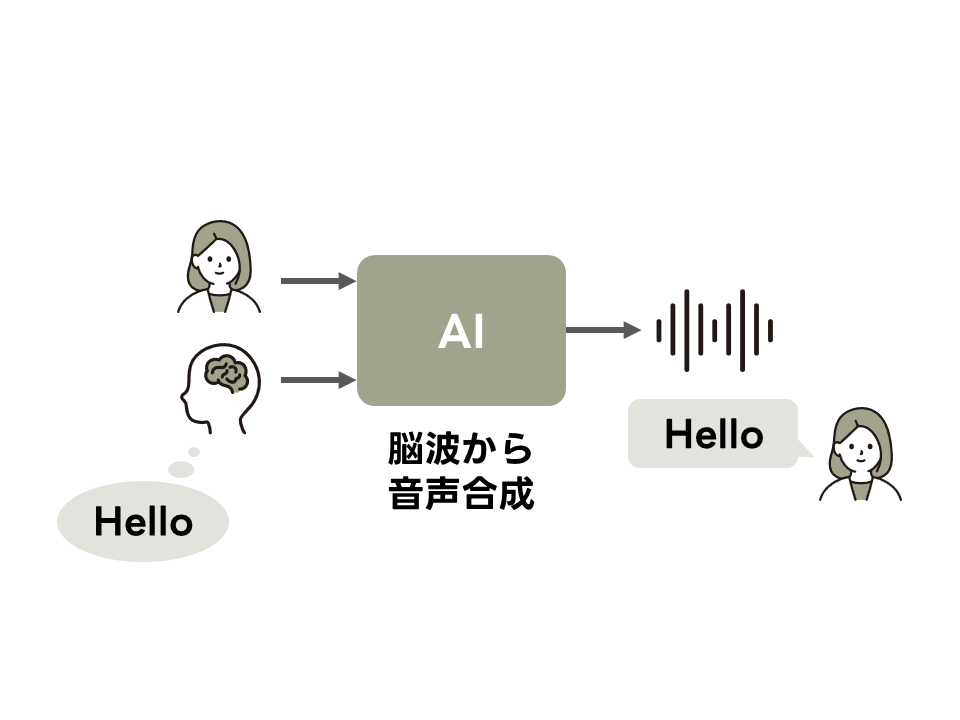
中鹿研究室では、脳波を活用する研究を行っています。
特に現在、脳波から音声を合成する研究を行っています。 言語的な情報だけでなく話者の個性や感情などの非言語的な情報を伝えられる音声を、脳波から直接合成できるようにすることで、次世代のコミュニケーション技術の確立を目指します。
この研究では、身体に負担を与えず比較的容易に測定できる脳波(EEG)を用います。 大量の脳波データを独自に収集し、最先端の音声合成手法やAIを応用します。 この研究が進めば、会話ができない方とのコミュニケーションのさらなる支援や、宇宙空間など会話をするのが困難な環境でのコミュニケーションが実現できるかもしれません。
なお、上記の研究は以下の題目で科研費の基盤研究(A)に採択されました。
「非侵襲型脳波を用いた言語・非言語音声合成による次世代コミュニケーション技術の確立」
中鹿研究室では、AI(機械学習・深層学習)のモデル構造に関する研究を行っています。
ここでは、機械学習とは「与えれたデータに基づいてプログラム内部のパラメータなどを自動で調整することで、あるタスクに対する性能指標を自動で改善するようなアルゴリズム」のことを指します。 また、深層学習とは「神経細胞の性質を模した人工ニューラルネットワークを多層に重ねたネットワークを利用する、機械学習手法の一種」のことを指します。
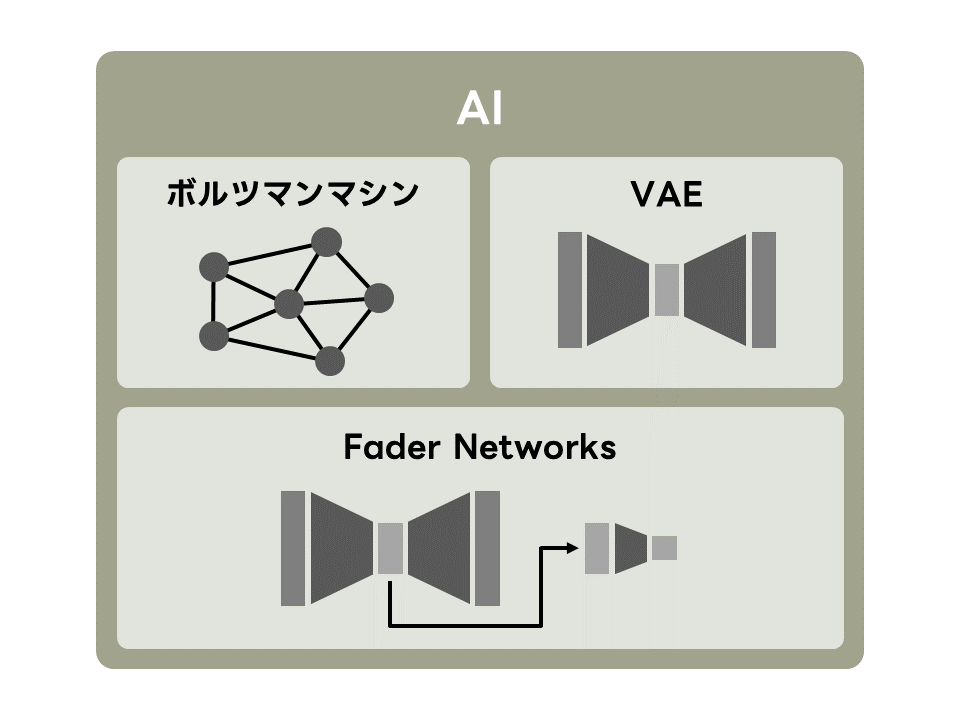
様々な種類の機械学習・深層学習モデルがある中で、特にボルツマンマシンやVAE、Fader Networksなどのモデル構造の工夫に取り組んでいます。 ボルツマンマシンは、磁性体や神経細胞の性質を模した機械学習モデルです。近年盛んに研究されている深層学習モデルの一般形と言えます。 VAEやFader Networksは、学習に用いたデータの特徴を持つ新しいデータを生成できる生成モデルと深層学習モデルを融合したモデルです。これらは、学習データに含まれる情報を分離(disentangled)する際によく利用されるモデルです。
機械学習モデルの構造を研究することで、音や脳波などの研究課題に特化したモデルを発見することや、モデルの各構成要素が果たす役割の解明、現実世界に存在するデータや構造の説明などを目指しています。